

- 地址:
- 海南省海口市
- 邮箱:
- admin@youweb.com
- 电话:
- 0898-08980898
- 传真:
- 1234-0000-5678
同义词挖掘一般有三种思路,借助已有知识库,上下文相关性,文本相似度。
1.1 知识库
可以借助已有知识库得到需要同义词,比如说《哈工大信息检索研究室同义词词林扩展版》和 HowNet,其中《词林》文件数据如下。
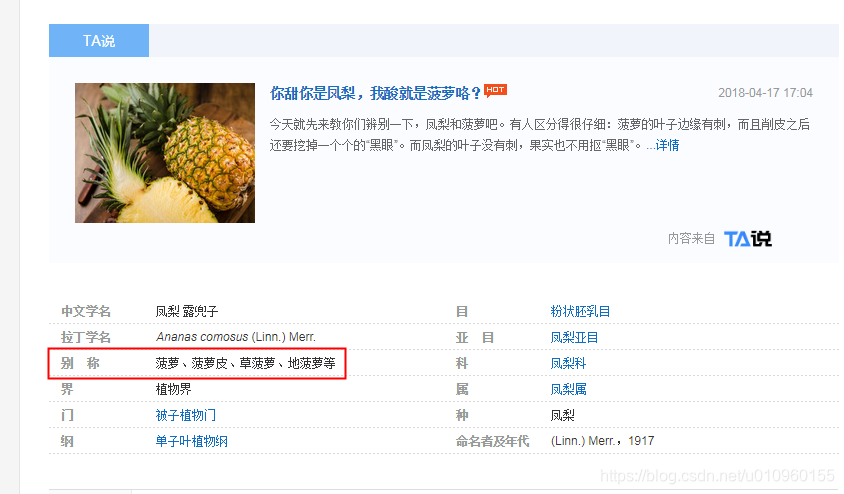
以上两个知识库是人工编辑的,毕竟数量有限,我们还可以借助众包知识库百科词条获取同义词,比如百度百科,如下图所示,在百度百科搜索“凤梨”,我们可以看到在返回页面结果中的 info box中有一个属性为“别称”,别称中就是凤梨的同义词。除此之外,在百科词条的开头描述中,有如下描述“又称”、“俗称”也是同义词,我们可以利用爬虫把这些词爬下来。
百度搜索和谷歌搜索等搜索工具一般都有重定向页,这也可以帮助我们去挖掘同义词。
使用知识库挖掘同义词的优点是简单易得,而且准确率也高,缺点就是知识库覆盖率有限,不是每个细分领域都有。对于金融、医疗、娱乐等领域都需要各自的知识库。
1.2? 上下文相关性
利用上下文相关性挖掘同义词也比较好理解,如果两个词的上下文越相似的话,那么这两个词是同义词的概率就越大。使用词向量挖掘同义词是比较常见的做法,比如使用word2vector训练得到词向量,然后再计算余弦相似度,取最相似的top k个词,就得到了同义词。
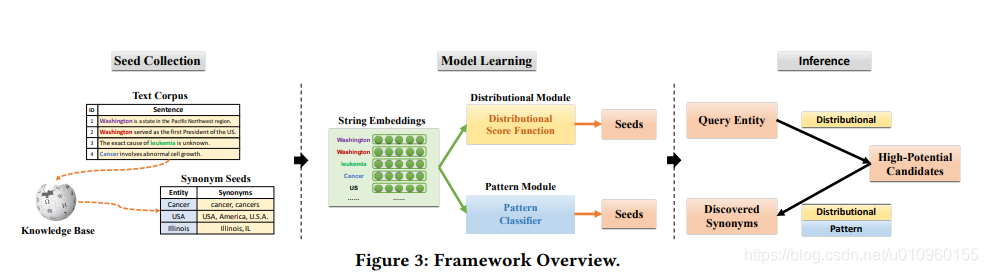
word2vector是无监督学习,而且本质上来说它是一个语言模型,词向量只是它的副产品,并不是直接用来挖掘同义词。有篇paper发明了弱监督的同义词挖掘模型DPE,也取得了不错的效果。DPE模型流程如下图,一共分为两个阶段,第一阶段跟word2vector差不多,也是训练词向量,只不过DPE是一种graph embedding的思路,首先从语料中构建语义共现网络,然后通过对网络的边采样训练词向量。第二阶段通过弱监督训练一个打分函数,对输入的一对词判断属于同义词的概率。感兴趣的可以看看这篇paper?论文链接
基于上下文相关性的同义词挖掘方法的优点是能够在语料中挖掘大量的同义词,缺点是训练时间长,而且挖掘的同义词很多都不是真正意义上的同义词需要人工筛选。这种方法对于词频较高的词效果较好。
1.3 文本相似度
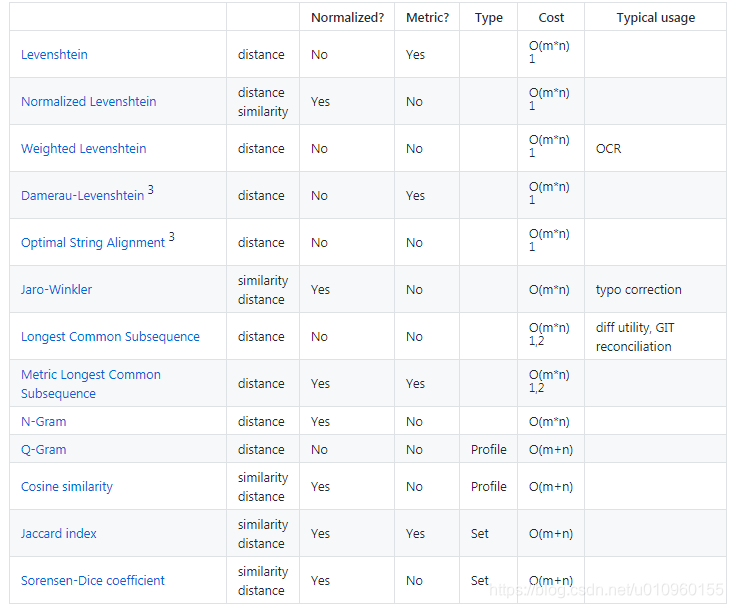
对于这一对同义词“阿里巴巴网络技术有限公司”和“阿里巴巴网络公司”直接去计算上下文相似度可能不太有效,那一种直观的方法是直接计算这两个词的文本相似度,比如使用编辑距离(Levenshtein distance)或者 LCS(longest common subsequence),如果两个词的文本相似度大于阈值的话我们就认为他们是同义词的关系。在这里推荐一个计算文本相似度的Java开源项目,基本上文本相似度算法应有尽有。[ 文本相似度算法 ]
基于文本相似度同义词挖掘方法的优点是计算简单,不同于word2vector,这种方法不需要使用很大的语料,只要这个词出现过一次就可以发现同义词关系。这种方法的缺点是有时候不太靠谱,会挖掘出很多错误的同义词,尤其是当两个词比较短的情况下,比如“周杰伦”和“周杰”,就可能会被认为是同义词。所以这种方法适用于一些较长的文本,特别是专业词汇,术语。
github地址:https://github.com/tigerchen52/synonym_detection
在这个github项目中实现了4种同义词挖掘的方法:
- 百度百科同义词
- word2vector?
- 语义共现网络的节点相似度
- Levenshtein距离
觉的有用同学记得点star~~
2.1?百度百科同义词
代码示例(synonym_detection/source/main.py)
输出
2.2?word2vector?
在这里使用《三体》小说作为训练语料,使用以下10个词作为输入,从语料中挖掘这10个词的同义词。后面几个方法使用相同的输入。
?代码示例
参数
- -corpus_path 为语料文件,使用三体小说作为训练语料
- -input_word_path 输入词表,对词表中的词进行同义词挖掘。文件中每行以“|”作为分隔符,第一列是id,第二列是输入词
- -process_number 2 进程数量
- -if_use_w2v_model True 使用word2vector模型
- 默认返回top 5个同义词
输出
2.2?语义共现网络的节点相似度
语义共现网络本质是根据上下文构建的图,图中的节点是词,边是这个词的上下文相关词。对于语义共现网络的两个节点,如果这两个节点的共同邻居节点越多,说明这两个词的上下文越相似,是同义词的概率越大。例如,对于《三体》小说中的两个词“海王星”和“天王星”,在《三体》语义共现网络中,“海王星”和“天王星”的邻居节点相似度很高,则说明两个词是同义词的可能性很高。如下图所示:

代码示例
输出
可以看出基于语义共现网络得到的同义词与word2vector结果类似,甚至在某些词上效果更好。
2.4?Levenshtein距离
代码示例
输出
?2.5?DPE模型
undo



