

- 地址:
- 海南省海口市
- 邮箱:
- admin@youweb.com
- 电话:
- 0898-08980898
- 传真:
- 1234-0000-5678
本文首先介绍基础梯度下降法,然后介绍对SGD的改进方法:动量法、AdaGrad、RMSprop以及Adam。本专栏的文章都是本人找工作时根据面试经历和网络资料整理,因此更偏向于要点罗列的形式。由于是为了应付面试,内容略显肤浅,且本人水平有限,若想在学术科研的层面有更深入的理解,还请参考相关论文以及大佬的文章。
梯度是一个向量,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向变化最快。梯度下降的主要思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降[这个意思是使得待优化函数例如Loss减小最快的参数更新方向]方向,所以也被称为”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。当目标函数是凸函数时,梯度下降的解时全局最优。但一般情况下,其解不保证全局最优。梯度下降原理推导(这个链接里的马东什么:梯度下降法和一阶泰勒展开的关系,很清晰),主要是理解为什么负梯度时下降最快的方向,为什么会有学习率这个东西,本质是对损失函数进行泰勒展开得到的。
在机器学习种,基于基本的梯度下降法,发展出了3种具体的梯度下降方法,分别为 BGD(Batch Gradient Descent批量梯度下降法),SGD, mini-batch GD
批量梯度下降法(Batch Gradient Desceent, BGD):具体做法也就是在更新参数时使用所有的样本来进行更新。 这样一来每迭代一步,都要用到训练集所有的数据,如果数据量很大,那么可想而知这种方法的迭代速度会很慢。
随机梯度下降(Stochastic Gradient Descent, SGD):每次迭代只用到了一个样本,在样本量很大的情况下,常见的情况是只用到了其中一部分样本数据即可迭代到最优解。因此随机梯度下降比批量梯度下降在计算量上会大大减少。SGD有一个缺点是,其噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。而且SGD因为每次都是使用一个样本进行迭代,因此最终求得的最优解往往不是全局最优解,而只是局部最优解。但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。
小批量梯度下降(Mini-batch Gradient Descent):小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,我们采用 x个样子来迭代,1<x<m 。
为了方便后续对SGD的改进方法的介绍,先介绍指数移动平均的概念。指数移动平均是以指数式递减加权的移动平均。 各数值的加权影响力随时间而指数式递减,越近期的数据加权影响力越重,但较旧的数据也给予一定的加权值。
计算公式为:
优点:当想要计算均值的时候,不用保留所有时刻的值。随着时间推移,遥远过去的历史的影响会越来越小
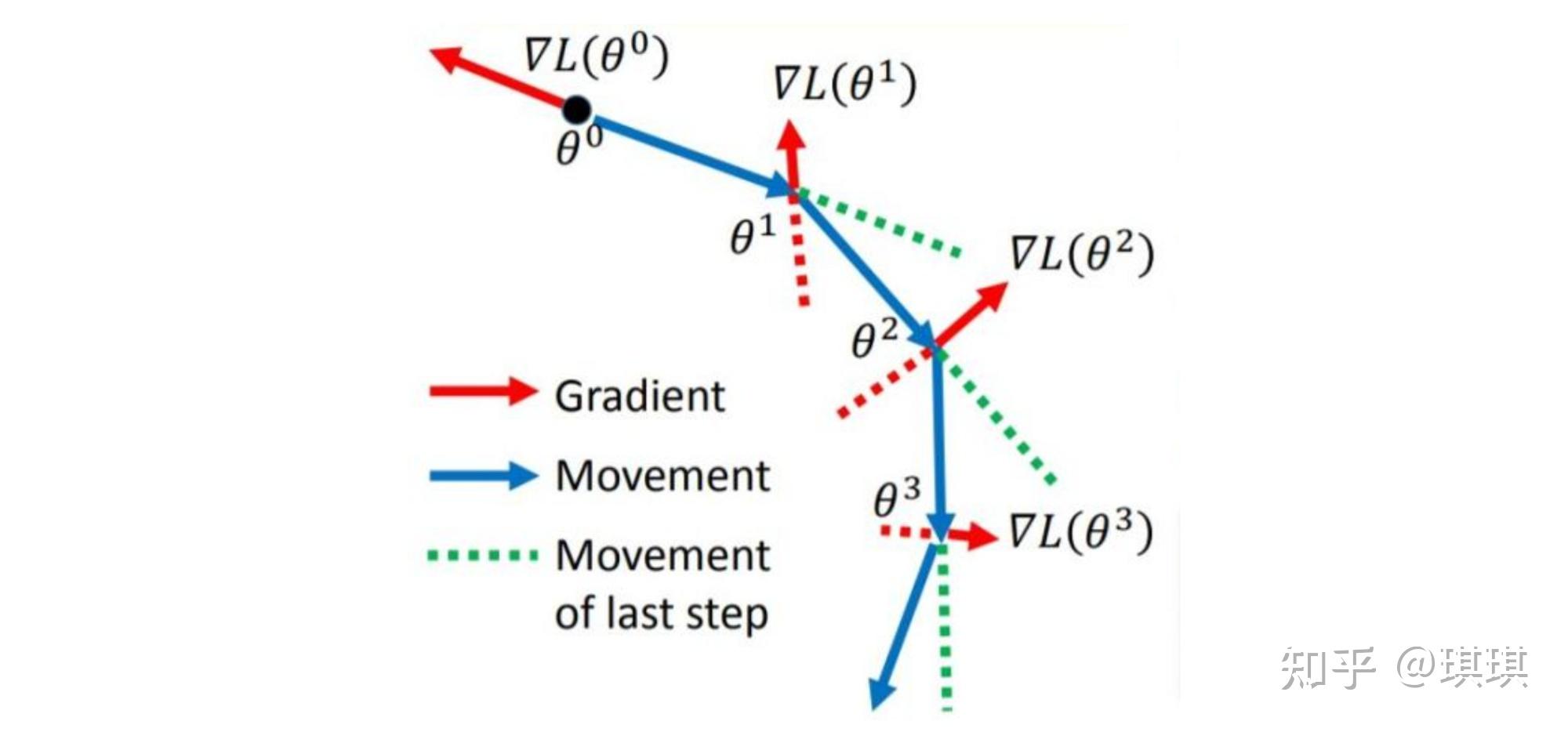
算法思想:参数更新方向不仅由当前的梯度决定,也与此前累积的梯度方向有关。将过去梯度的指数移动平均称为动量。当前参数的更新值由动量和当前梯度两部分确定。在当前梯度方向发生改变时(震荡通常发生在梯度方向改变的时候),动量能够降低参数更新的速度,从而减少震荡;当前梯度方向与之前的梯度方向相同时,动量能够加速参数更新,从而加速收敛。
参数更新:
参数 决定了之前的梯度的贡献衰减的速度。当
时,动量法就是SGD。
算法流程:

算法思想:之前的SGD、动量法对每个参数都使用相同的学习率,AdaGrad对不同的参数动态采取不同的学习率。对于每个参数,其学习率为全局学习率除以该参数历史梯度平方和的平方根。在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。缺点:由于累计梯度平方和,训练中后期,分母越来越大,导致学习率很快会接近0。
参数更新:
表示Hadamard乘积(向量对应位置的元素相乘),
是全局学习率。
算法流程:

基本思想:RMSprop也是一种自适应学习率的方法,是在AdaGrad上的改进。AdaGrad会累计之前所有的梯度平方,而RMSprop采用的是指数加权移动平均,能够丢弃掉遥远过去的历史梯度平方,从而缓解AdaGrad学习率随迭代次数下降过快的问题。
参数更新:
算法流程:

基本思想:也是一种自适应学习率的方法,可以看作是结合了RMSProp和动量法。Adam同时具备Momentum和RMSprop的优点。一是记录了过去的梯度,使用过去的累积梯度(动量)和当前梯度共同确定当前参数的更新量,可以减小震荡,加速收敛。而是使用梯度平和的累积值来动态调整学习率。
算法流程:

Adam详细参数说明可以参见https://blog.csdn.net/sinat_36618660/article/details/100026261
https://zhuanlan.zhihu.com/p/29920135
深度学习花书
https://zhuanlan.zhihu.com/p/32626442
https://zhuanlan.zhihu.com/p/29895933
https://blog.csdn.net/sinat_36618660/article/details/100026261
上述内容是本人去年找工作的时候整理的,参考了网络上很多资料,有些资料没有记录来源。如有雷同,那一定是本人搬运了~



