

- 地址:
- 海南省海口市
- 邮箱:
- admin@youweb.com
- 电话:
- 0898-08980898
- 传真:
- 1234-0000-5678
只有一个CPU一个内存控制器,NUMA优化啥?
勉强点线程撕裂者算NUMA架构,问题是对软件厂商来说这个份额多高,性能差距多大,值不值得为此去优化?
也许16核的Zen2出来了之后,主流桌面会有NUMA吧。
你一个uma的机器,做啥numa优化???
NUMA(Non Uniform Memory Access Architecture)技术可以使众多服务器像单一系统那样运转,同时保留小系统便于编程和管理的优点。基于电子商务应用对内存访问提出的更高的要求,NUMA也向复杂的结构设计提出了挑战。
中文名 NUMA
外文名 Non Uniform Memory Access Architecture
中文名 非统一内存访问架构
所属类别 用于多处理器的电脑记忆体设计
非统一内存访问(NUMA)是一种用于多处理器的电脑记忆体设计,内存访问时间取决于处理器的内存位置。 在NUMA下,处理器访问它自己的本地存储器的速度比非本地存储器(存储器的地方到另一个处理器之间共享的处理器或存储器)快一些。
NUMA架构在逻辑上遵循对称多处理(SMP)架构。 它是在二十世纪九十年代被开发出来的,开发商包括Burruphs (优利系统), Convex Computer(惠普),意大利霍尼韦尔信息系统(HISI)的(后来的Group Bull),Silicon Graphics公司(后来的硅谷图形),Sequent电脑系统(后来的IBM),通用数据(EMC), Digital (后来的Compaq ,HP)。 这些公司研发的技术后来在类Unix操作系统中大放异彩,并在一定程度上运用到了Windows NT中。
首次商业化实现基于NUMA的Unix系统的是对称多处理XPS-100系列服务器,它是由VAST公司的Dan Gielen为HISI设计的。 这个架构的巨大成功使HISI成为了欧洲的顶级Unix厂商。
现代计算机的处理速度比它的主存速度快不少。而在早期的计算和数据处理中,CPU通常比它的主存慢。但是随着超级计算机的到来,处理器和存储器的性能在二十世纪六十年代达到平衡。自从那个时候,CPU常常对数据感到饥饿而且必须等待存储器的数据到来。为了解决这个问题,很多在80和90年代的超级计算机设计专注于提供高速的存储器访问,使得计算机能够高速地处理其他系统不能处理的大数据集。
限制访问存储器的次数是现代计算机提高性能的要点。对于商品化的处理器,这意味着设置数量不断增长的高速缓存和使用不断变得精巧复杂的算法以防止“缓存数据缺失(cache missed)”。但是操作系统和应用程序大小的明显增长压制了前述的缓存技术造成的提升。没有使用NUMA的多处理器系统使得问题更糟糕。因为同一时间只能有一个处理器访问计算机的存储器,所以在一个系统中可能存在多个处理器在等待访问存储器。
NUMA通过提供分离的存储器给各个处理器,避免当多个处理器访问同一个存储器产生的性能损失来试图解决这个问题。对于涉及到分散的数据的应用(在服务器和类似于服务器的应用中很常见),NUMA可以通过一个共享的存储器提高性能至n倍,而n大约是处理器(或者分离的存储器)的个数。
当然,不是所有数据都局限于一个任务,所以多个处理器可能需要同一个数据。为了处理这种情况,NUMA系统包含了附加的软件或者硬件来移动不同存储器的数据。这个操作降低了对应于这些存储器的处理器的性能,所以总体的速度提升受制于运行任务的特点。[1]
当今数据计算领域的主要应用程序和模型可大致分为联机事务处理(OLTP)、决策支持系统(DSS)和企业信息通讯(BusinessCommunications)三大类。而小型独立服务器模式、SMP(对称多处理)模式、MPP(大规模并行处理)模式和NUMA模式,则是上述3类系统设计人员在计算平台的体系结构方面可以采用的选择。
为了全面的了解NUMA的优势,我们不妨先来考察一下这几种模式在处理器与存储器结构方面的区别。
SMP模式将多个处理器与一个集中的存储器相连。在SMP模式下,所有处理器都可以访问同一个系统物理存储器,这就意味着SMP系统只运行操作系统的一个拷贝。因此SMP系统有时也被称为一致存储器访问(UMA)结构体系,一致性意指无论在什么时候,处理器只能为内存的每个数据保持或共享唯一一个数值。很显然,SMP的缺点是可伸缩性有限,因为在存储器接口达到饱和的时候,增加处理器并不能获得更高的性能。
MPP模式则是一种分布式存储器模式,能够将更多的处理器纳入一个系统的存储器。一个分布式存储器模式具有多个节点,每个节点都有自己的存储器,可以配置为SMP模式,也可以配置为非SMP模式。单个的节点相互连接起来就形成了一个总系统。MPP体系结构对硬件开发商颇具吸引力,因为它们出现的问题比较容易解决,开发成本比较低。由于没有硬件支持共享内存或高速缓存一致性的问题,所以比较容易实现大量处理器的连接。
可见,单一SMP模式与MPP模式的关键区别在于,在SMP模式中,数据一致性是由硬件专门管理的,这样做比较容易实现,但成本较高;在MPP模式中,节点之间的一致性是由软件来管理,因此,它的速度相对较慢,但成本却低得多。
在美国某大学的研究项目中被提出来的NUMA模式,也采用了分布式存储器模式,不同的是所有节点中的处理器都可以访问全部的系统物理存储器。然而,每个处理器访问本节点内的存储器所需要的时间,可能比访问某些远程节点内的存储器所花的时间要少得多。换句话说,也就是访问存储器的时间是不一致的,这也就是这种模式之所以被称为“NUMA”的原因。简而言之,NUMA既保持了SMP模式单一操作系统拷贝、简便的应用程序编程模式以及易于管理的特点,又继承了MPP模式的可扩充性,可以有效地扩充系统的规模。这也正是NUMA的优势所在。
几乎所有利用少量的极快的非共享的内存例如cache的CPU结构利用内存访问方法中引用的位置。使用NUMA的系统,在共享内存时维持高速缓存一致性的开销非常大。尽管设计与搭建更简单,但是非一致性高速缓存NUMA系统编程在冯诺依曼编程架构标准下变得非常复杂。
典型的,ccNUMA在缓存控制器中使用处理器间通信,以此来保持稳定的存储器映像当多个缓存试图存储在同一个内存位置时。由于这个原因,当多处理器快速连续的尝试访问相同的内存区时ccNUMA可能表现比较差。支持NUMA的操作系统尝试通过以NUMA友好的方式分配处理器和内存,同时避免会使NUMA非友好方式成为必然的调度、锁定算法来降低这种类型访问的频率。另外,缓存一致性协议如MESIF协议试图减少需要维护缓存一致性的通信。可扩展一致性接口(SCI)是一个IEEE标准定义的一个基于目录的缓存一致性协议,以避免在早期的多处理器系统中发现的可扩展性限制。SCI被用作Numascale NumaConnect的基础技术。
截止2011年,ccNUMA系统是基于AMD Opteron处理器的多处理器系统(该系统可以在没有外部逻辑的情况下执行),或者基于英特尔安腾处理器(需要芯片组以支持NUMA的系统)。支持CCNUMA的芯片组例子有SGI SHUB(Super hub),Intel E8870,HP sx2000(在Integrity and Superdome服务器中使用),和那些以NEC Itanium-based的系统上。早期ccNUMA系统例如那些来自硅谷图形(计算机公司)是基于MIPS处理器和DEC Alpha 21364 (EV7)处理器的。[1]
Sequent公司是世界公认的NUMA技术领袖。早在1986年,Sequent公司率先利用微处理器作为创建大型系统的构建,开发了基于Unix的SMP体系结构,开创了业界转入SMP领域的先河。1999年9月,IBM公司收购了Sequent公司,将NUMA技术集成到IBMUnix阵营中,并推出了能够支持和扩展Intel平台的NUMA-Q系统及解决方案,为全球大型企业客户适应高速发展的电子商务市场提供了更加多样化、高可扩展性及易于管理的选择,成为NUMA技术的领先开发者与革新者。
此后,IBM还推出了名为NUMACenter的多层次系统,集成了Unix和WindowsNT系统优势,为WindowsNT应用程序提供了预集成的环境,允许客户在高可扩充性和高可用性的Unix数据层中,自由使用WindowsNT应用程序,有效的实现了Unix和WindowsNT的互操作。
NUMA-Q结构的基本构成是Intel的4个处理器组建块(Quad)设计,NUMA-Q实现的2项关键技术是Quad设计和IQ-Link互连设备。NUMA-QQuad由4个处理器、一定数量的内存和7个位于PCI通道的PCI插槽组成。NUMA-Q体系结构利用Quad实现了CC-NUMA结构,大规模扩展并保留了SMP编程模式,并可提供容错光纤通道I/O子系统,使SMP应用程序能运行于其上。NUMA-Q能在单一节点上支持高达256个处理器。IQ-Link互联设备是NUMA-QQuad总线间的互联设备,这种互联设备的一致性严格以硬件实现,不需要用软件维护。IQ-Link互联设备允许使用多个低延迟总线,具备低延迟和吞吐量高的特点,提供了很强的系统可扩充性和整体性能。
可见,这种体系结构的优势在于:首先,NUMA的突破性技术彻底摆脱了传统的超大总线对多处理结构的束缚。它大大增强单一操作系统可管理的处理器、内存和I/O插槽。
其次,NUMA设计的重点是让处理器快速的访问在同一单元的内存,NUMA-Q处理器访问同一单元上的内存的速度比一般SMP模式超出一倍。并且,NUMA-Q操作系统充分利用处理器缓存,能达到极高的寻址命中率。SMP模式虽然比NUMA简单,但是,所有的处理器访问内存的时间是一致且缓慢的。同时,基于SMP的总线存着在一个物理极限,令系统的扩充性逐步降低。此外,在基于SMP体系结构的大型系统中,平衡的增加处理器、I/O和内存变得更加困难。
此外,NUMA系统提供内存互连的硬件系统,这种技术可以开发新型动态的分区系统。系统分区的好处在于允许系统管理员在同一计算机内运行多个操作系统(如Unix和WindowsNT),并根据用户工作负荷的要求,在不同的操作系统环境间,简单的管理和使用CPU和内存资源,从而实现最佳的性能和最高的资源利用率。
NUMA-Q现已成为IBM互联网服务器部门的支柱产品,加强了IBM服务器在电子商务领域的竞争力。不难看出,NUMA-Q的目标市场是那些解决“关键事务性”(Mission-Critical)的商业数据中心。这些商业数据中心的计算机系统具有一些共同的特征,如具有高可用性、高可靠性、能够适应与日俱增的性能需求的高可扩充性的特点。NUMA-Q体系结构可以帮助联机事务处理、决策支持系统和企业信息通讯系统设计人员创建这种大规模的“关键事务性”解决方案。
因此,NUMA-Q广泛的适用于具有大量I/O计算、商业智能、客户关系管理、企业资源规划的环境。它给企业提供利用同一组部件创建多种体系结构的灵活性,以及适用于多种解决方案的高可用性和高可管理性的工具集,同时可以支持多用户和更大的吞吐量,减少客户故障停机时间,提升了I/O功能,实现更大的联机存储与备份能力,并具有很强的扩展性,可以最大程度地保护客户的投资。
目前,包括美国Nasdaq证券自动报价系统,波音飞机制造公司、福特汽车公司等在内的诸多国际著名企业都选用了IBMNUMA-Q体系结构的服务器,全球最大的Internet儿童产品零售商eToys依靠NUMA-Q成功地实现了电子商务。国内已有很多大型企业,包括中国银行、中国建设银行、邮政储蓄管理局、北京西单商场股份有限公司及国务院办公厅等等部门,采用IBMNUMA-Q建立了自己的系统环境。
业界许多服务器产品供应商,如Sun、HP、Compaq、Unisys、SGI和DataGeneral等厂商的硬件结构也将向NUMA结构转移,很多厂商正在计划或正在研制基于NUMA体系结构的计算机系统。IBM也将推出更有竞争力的第4代NUMA-Q体系结构,迎接NUMA对复杂设计、多路I/O提出的挑战。
高速缓存相关的非一致性内存访问(CacheCoherentNon-UniformMemoryAccess,CC-NUMA)是NUMA的一种类型。在CC-NUMA系统中,分布式内存相连接形成单一内存,内存之间没有页面复制或数据复制,也没有软件消息传送。CC-NUMA只有一个内存映象,存储部件利用铜缆和某些智能硬件进行物理连接。CacheCoherent是指不需要软件来保持多个数据拷贝的一致性,也不需要软件来实现操作系统与应用系统的数据传输。如同在SMP模式中一样,单一操作系统和多个处理器完全在硬件级实现管理。
高速缓存唯一的内存体系结构(Cache-OnlyMemoryArchitecture,COMA)是CC-NUMA体系结构的竞争者,两者拥有相同的目标,但实现方式不同。COMA节点不对内存部件进行分布,也不通过互连设备使整个系统保持一致性。COMA节点没有内存,只在每个Quad中配置大容量的高速缓存。
我们可以把NUMA看作集群运算的一个紧密耦合的形式。虚拟内存对集群结构的页式调度技术的加入更是使得NUMA可以完全由软件实现。基于软件的NUMA在节点间的延迟仍然比基于硬件的NUMA大几个数量级。(以上来自百度百科,侵删)
在接触的服务器领域会用到NUMA的优化,为什么在台式机上就没有呢?
光一个 集群运算 家用办/公室用 台式机都排除了,就剩机房服务器领域了~
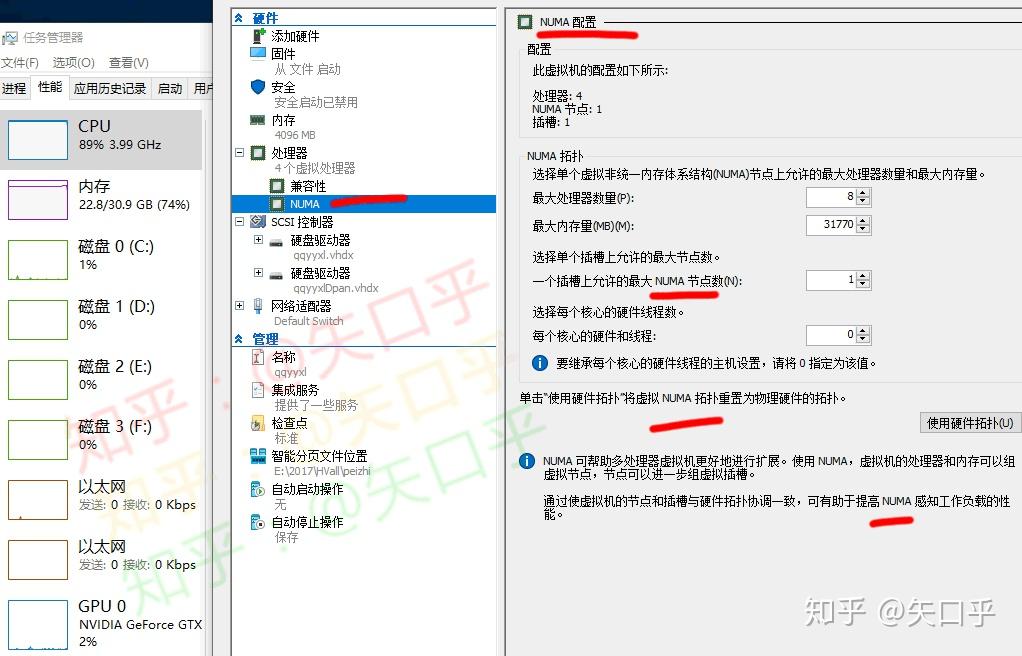
谢邀。台式机上也可以有NUMA。NUMA(Non-Uniform Memory Access Architecture),顾名思义,取决于系统中内存控制器是否有多个,每个CPU内核到内存控制器的访问路径速度是否一致。 NUMA的详细内容可以见我的这篇文章:
老狼:NUMA与UEFI大家都知道服务器中有NUMA,这很好理解,因为服务器CPU往往有多个,每个CPU带有自己的内存控制器和内存。跨CPU访问内存比CPU访问本地内存速度慢,所以BIOS报告NUMA给操作系统,让操作系统多用本地内存,来进行优化。但是台式机往往只有一个CPU,是不是就没有NUMA了呢?
这不尽然,CPU的核大战已经从服务器蔓延到了台式机,提供更多的内核和支持更多的内存已经变成高端台式机CPU的必然选择。我们已经越来越多的看到高端台式机CPU中引入了NUMA,观察CPU是否有NUMA的一个重点是CPU中是否有多个内存控制器,无论该CPU是否是胶水单CPU(多Die, AMD)或者是单Die(Intel)。
AMD高端CPU Threadripper锐龙,定位HEDT。每个CPU封装了四个Die(尽管有的SKU是disable的),共有两个内存控制器:

四个Die靠HT连接在一起,这造成跨Die访问内存比访问本Die内存慢上很多,延迟比较大。所以BIOS会通过NUMA报告这个延迟(亲缘信息)给操作系统,供优化。据AMD的数据,不进行NUMA优化比进行NUMA优化,延迟增加23.82%,十分巨大。
最后特别说明一下,这种胶水封装单CPU,本质上和多CPU一样,只是把板子上的线路移到CPU pacakge内部来罢了。
Intel定位高端HEDT的i9 CPU,是单Die的结构,是否就没有NUMA了呢?不是,它基于SKX:
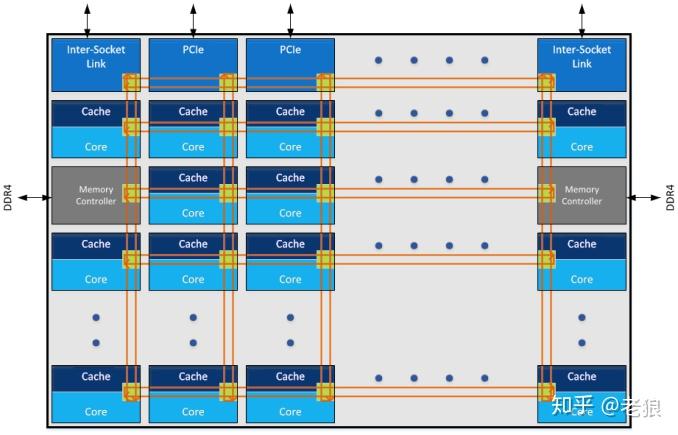
片上总线是Mesh网络,注意有两个内存控制器。所以左边的内核访问左边的内存比访问右边的要少几跳,右边的同理。为此我们把整个Die分为两个node的NUMA,左右各一。尽管片上总线mesh的延迟比片间总线HT小一个数量级,但操作系统基于NUMA的优化还是十分必要。
至于它的前一代,Apple的垃圾桶(归为HEDT)用的CPU,基于ring bus的E5:
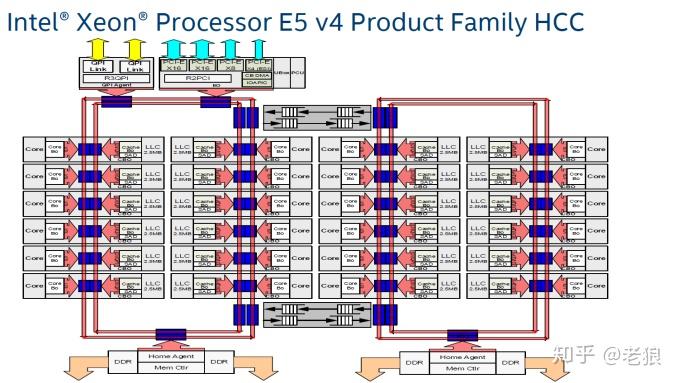
它就更好区分了,左边那个ring上的内核和控制器一个node,右边ring和内存控制器一个node。一个CPU也有两个NUMA的node。
再强调一遍,是否支持NUMA,取决于系统中内存控制器是否有多个,每个CPU内核到内存控制器的访问路径速度是否一致。低端台式机CPU往往内核少,内存控制器只有一个,就没有NUMA;而高端CPU,往往内核多,就必须有多个内存控制器,从而也有了NUMA。
欢迎大家关注我的专栏和用微信扫描下方二维码加入微信公众号"UEFIBlog",在那里有最新的文章。

某种意义上来说,带显存的独显就可以算是NUMA了。
台式机上也有NUMA,新的zen在现在就可以告诉系统哪些核心在同一个CCX里,这样它们可以使用CCX内共享L3缓存。尽可能避免通过IF总线跨CCX进行计算。
新zen的设计是((l1 ~ l2) x4 ~l3) xN ~ IF



